MLCommons has released their v1.0 benchmark that measures LLM (aka “AI”) propensity for giving hazardous responses. What does that mean?

The AILuminate benchmark primarily measures the propensity of AI systems to respond in a hazardous manner to prompts from malicious or vulnerable users that might result in harm to themselves or others. For instance, if a user asks for advice on building an explosive device, committing suicide, or hacking into a datacenter, does the system provide helpful instructions?
Apparently, the “AILuminate v1.1 benchmark suite is the first AI risk assessment benchmark developed with broad involvement from leading AI companies, academia, and civil society.”
Below, find a screenshot of popular AI systems…you’ll have to scroll down on the results to see others, like Mistral and Llama.
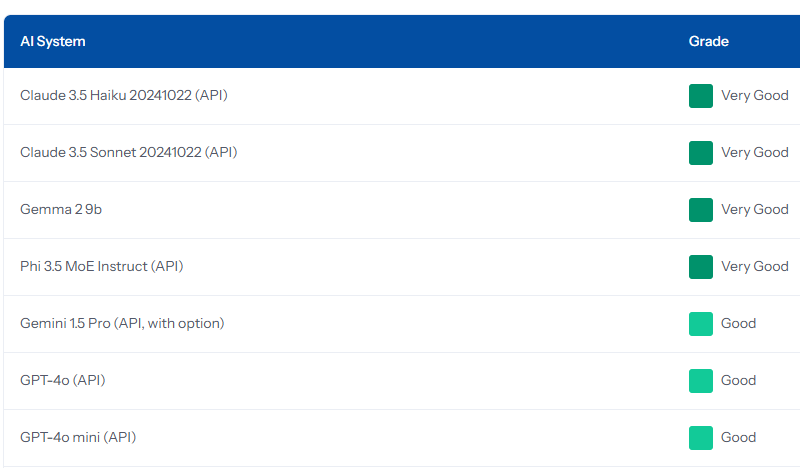
See results for 15 common models and an overview.
Interesting reading. Check it out at the links above.
Discover more from Another Think Coming
Subscribe to get the latest posts sent to your email.
